
Glossary
1. WDE Pro Toolbar
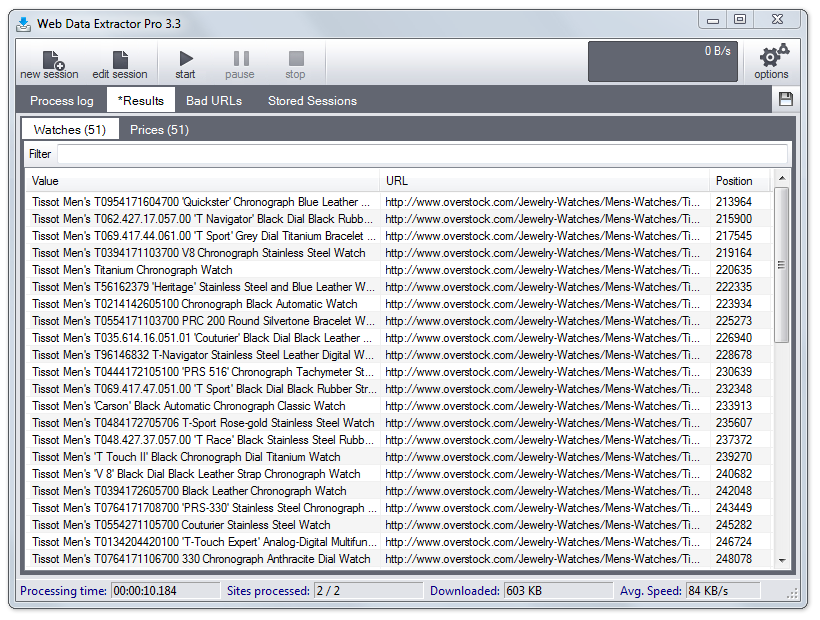
The Web Extractor toolbar provides one-click access to the application most frequently used Main menu items as well as provides you with the statistic information about current extraction session.
New session
A dialog with various session settings (such as search engines, retrieval depth, etc.)
Edit session
Enables to modify parameters of a session that has not been started. The button is disabled when the session is in progress. If you want to edit a session that has been started, press Pause/Stop, then press Edit Session button and finally, in Session dialog press New Session.
Start
Run specified (current or stored) session
Pause
Interrupt or resume session running
Stop
Interrupt session running (enables to create new session)
Diagram
Representation of the current extraction speed graphically and through data rates measurement (in bits per second)
Options
General and more specific (connection, search engines, parser) settings. Once specified, they will be applied to all following sessions.
General
Temp path
The path of program temporary folder
Output path
The path of Results folder
Encoding
Type of Results encoding
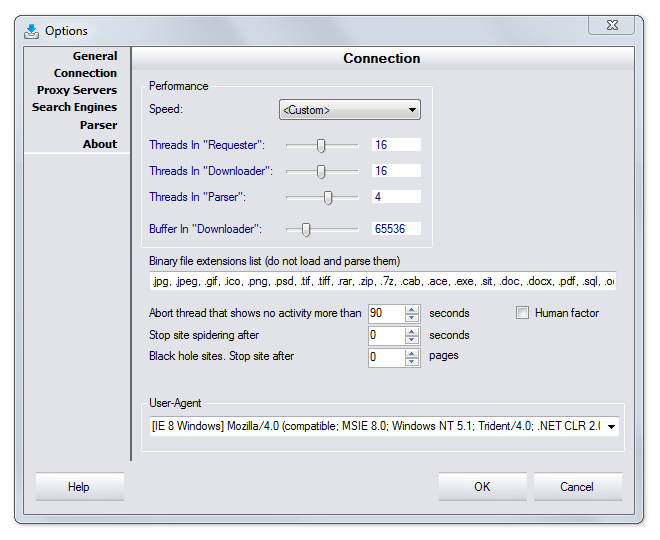
Connection
Performance
WDE is a multithreaded spider, that is it can simultaneously visit different web pages. You can set the number of threads on the requester, downloader and parser separately. This controls the number of separate threads or connections that program will use to extract data for the project. Remember, that the more threads you choose the more you load your computer, Internet connection and host server which may actually slow the process down.
Human factor
Inserting a random delay between queries. This sometimes makes a website think that it is visited by a person, not a spider. So this site does not apply any preventive measures.
User agent
The identity of WDE when communicating with remote servers
Proxy
Proxy option gives you an opportunity to compose and upload proxy servers list and extract more information with it.
Search engines
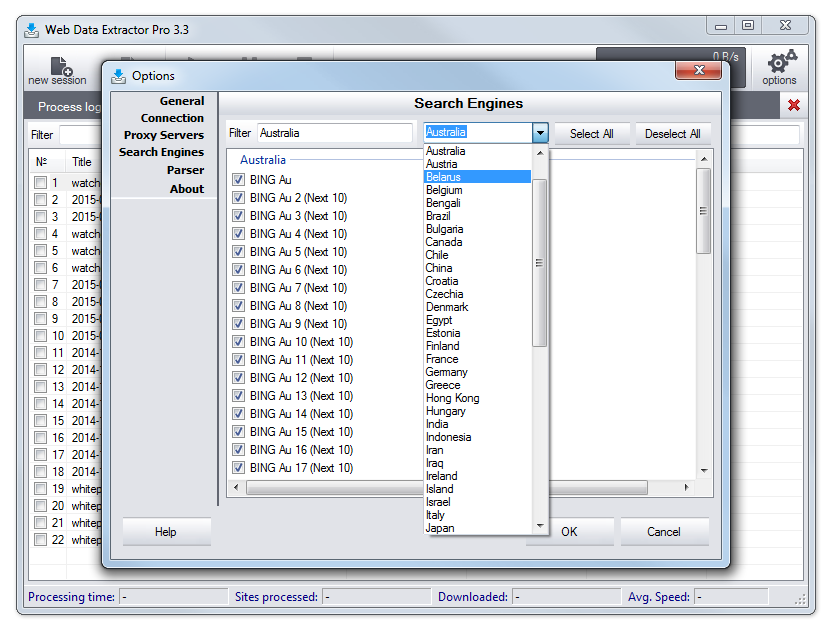
You can choose search engine(s) of 64 different countries. Settings of this dialog will be saved for all future sessions until you change them. Unlike settings entered in New Session dialog → Data Source → Search Engines → Select Search Engines dialog, that will be valid only for one session.
Parser
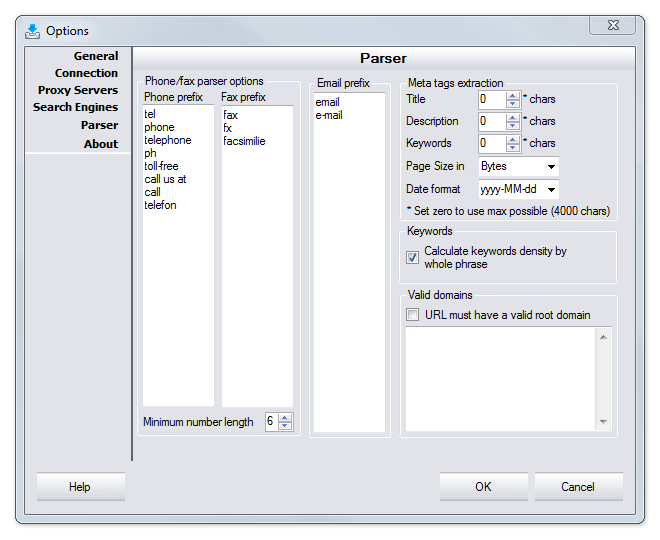
Phone/fax parser options
Enter phone/fax prefix for WDE to distinguish corresponding data type
Email prefix
Enter email prefix for WDE to distinguish corresponding data type
Meta tags extraction
Set the number of characters that Title, Description and Keywords may contain (displayed in Results). You can also choose size unit (to be displayed in Process Log, Results) and date format (to be displayed in Session Name, Results and Stored Sessions).
Valid domains
Check this option so that all extracted data is verified against domain list. By default it is always checked. To add new or additional domain open "DomainList.txt" file in program installation folder and edit it using NotePad or other text editor.
About
Learn more about WDE Pro in Help, download new tools for your program or report us about a problem
Process log
Logging form containing information on session running process
Results
Various information on data types (URLs, domains, meta tags, emails, phones, faxes) you've chosen to extract. In this mode Save results button in upper right corner is active.
Bad URLs
URLs that WDE had problems visiting. In this mode Save Bad URLs button in upper right corner is active.
Stored sessions
A list of session (and groups of sessions) names with start/pause/stop information. Use Filter for quick search through session (group) names. In this mode Delete Stored Sessions button in upper right corner is active. To start selected stored session press Start button. To create a new session based on the settings of one of the stored sessions – double-click on one of the stored sessions and click New Session in the opened dialog. To view Results of a stored session – double-click one and then close the emersed dialog.
Save
This button is active only for Results and Bad URLs mode. A dialog that opens will help you to customize saving process. WDE Pro saves data in comma separated value format (CSV). CSV file can be exported to Excel, OpenOffice.org Calc, Apple Numbers, Google Docs & Spreadsheets, many databases, etc.
2. Session
A dialog with various session settings (such as search engines, retrieval depth, etc.).
Note: Before launching new session, always make sure that it doesn't contain settings from the previous project (filters, custom data, etc.).

General
Session name
By default consists of session creation time and website URL/keywords put in the entry field
Group
Enter the name of the group and all following sessions will belong to the set group. This will organize collected session data. Use Filter to simplify the output of required session information in Stored Sessions.
Timeline
Indicates timeline of the Stored Session
New session
Current session status. When one of the Stored Sessions is activated, this status is changed to: Started (dd.mm.yy hh:mm:ss), Paused (dd.mm.yy hh:mm:ss), and, if session was finished – Finished (dd.mm.yy hh:mm:ss).
Data source
Site
Information extraction from a specified website. In this mode WDE will retrieve html/text pages of the website according to the depth you specifiy and extract all data found in those pages.
Start URL
Enter an URL that you want WDE to start searching from: a domain name or specific domain sub-directory
Depth
Distance between a directory containing Start URL and a directory that we want to be spidered last. The index of depth tells WDE how many levels to dig down within the specified domain. By default maximal depth (10) is selected. Depth option is customizable only in Site and URL List section. It does not work in Search Engines section.
Example:
Negative depth:
Depth = -10 (maximum): WDE looks for data 10 levels up from the start level
Depth = -3: WDE goes one more level up and spiders all subdirectories found in all directories at depth 1, -2
Depth = -2: WDE goes one level up from the start level and spiders all subdirectories of start level directories
Depth = -1: same as depth 1
Depth = 0:WDE visits ONLY pages of the Start URL directory. It does not search in other folders within start folder. Start URL is always at a depth 0.
Positive depth:
Depth = 1: WDE stays on the start level and spiders ALL directories within this level
Depth = 2: WDE goes one level down from the start level and spiders all subdirectories of start level directories
Depth = 3: WDE goes one more level down and spiders all subdirectories found in all directories at depth 1, 2
Depth = 10 (maximum): WDE looks for data 10 levels down from the start level
Depth = -4: http://www.xyz.com/index.htm
Depth = -3: http://www.xyz.com/W/product.htm
Depth = -2: http://www.xyz.com/W/D/download.htm
Depth = 0: http://www.xyz.com/W/D/E/purchase.htm
Depth = 1: http://www.xyz.com/W/D/E1/modules.htm
Depth = 2: http://www.xyz.com/W/D/E/P/help.htm
Depth = 3: http://www.xyz.com/W/D/E/P/R/faq.htm
Depth = 4: http://www.xyz.com/W/D/E/P/R/O/support.htm
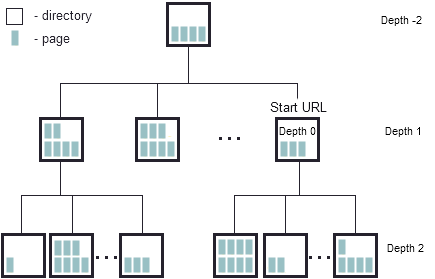
To spider (process, visit) a directory (folder) means to spider every web page (file) in it. To reach specified depth WDE spiders a site consistently undergoing all previous layers.
One page only
WDE stays only within the default page of specified start URL
Offsite
WDE can retrieve files of external sites that are linked to the site specified in Start URL box. By default, WDE will follow external sites only once, that is (1) WDE will process starting address and (2) all external sites found in starting address. It will not follow all external sites found in (2) and so on. In the Offsite mode the program spiders both start URL and all offsite URLs on maximal depth. WDE is powerful, so remember to stop WDE sesssion manually, because this way WDE can travel entire Internet.
Positive
Search in lower levels comparing with the Start level
Negative
Search in upper levels comparing with the Start level
Example:
WDE is going to visit URL http://www.xyz.com/product/milk/ for data extraction. The structure of this process is as follows:
| URL | URL Depth | Selected Depth | |||||
|---|---|---|---|---|---|---|---|
| <=-3 | -2 | -1 | 0 | 1 | >=2 | ||
| http://www.xyz.com/ | -3 | x | |||||
| http://www.xyz.com/support.htm | -3 | x | |||||
| http://www.xyz.com/about.htm | -3 | x | |||||
| http://www.xyz.com/product/ | -2 | x | x | ||||
| http://www.xyz.com/product/support.htm | -2 | x | x | ||||
| http://www.xyz.com/product/milk/index.htm | One Page only | x | x | x | x | x | x |
| http://www.xyz.com/product/milk/ | 0 | x | x | x | x | x | x |
| http://www.xyz.com/product/milk/baby/ | 2 | x | |||||
| http://www.xyz.com/product/milk/baby/page1.htm | 2 | x | |||||
| http://www.xyz.com/product/milk/baby/page2.htm | 2 | x | |||||
| http://www.xyz.com/product/water/ | 1 | x | x | ||||
| http://www.xyz.com/product/water/mineral/ | 2 | x | |||||
| http://www.xyz.com/product/water/mineral/news.htm | 2 | x | |||||
Search engines
Information extraction from all specified search engines. In this mode WDE sends queries to specified search engines to get matching website URLs from search results. Next it removes duplicate URLs. Finally, it visits those URLs to extract data from them.
Keyword
A word or phrase (that together with other words or phrases) relevantly represent a topic
Select search engines
You can choose search engine(s) of 64 different countries. Settings of this dialog will be valid only for one session. Unlike settings entered in Options → Search Engines dialog, that will be saved for all future sessions until you change them.
URL list
Information extraction from a text file containing a list of URLs. In this mode WDE will visit websites from the list of URLs one-by-one according to the depth you specify. WDE accepts URLs that point to root directory as well as URLs pointing to specific html file.
File
Enter the file name that contains all URL links to process or browse it from your computer
Browse
Choose the file containing list of URLs. This must be plain text file with one URL per line, each line starting with http://
Open
Click this button to look through the browsed file
URL filter
Set of URL adjustments to customize data extraction.
Note: Most of the sites are case-insensitive. So by default WDE ignores case of URLs, which means it regards two following URLs as same:
http://www.abc.com
http://WWW.ABC.COM
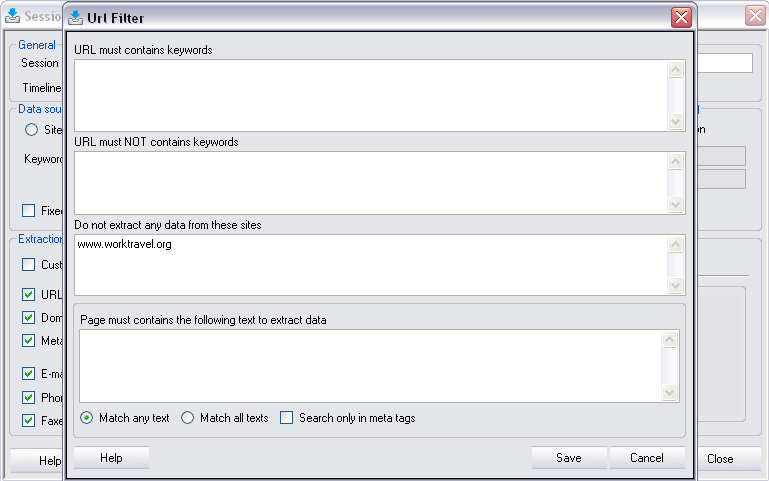
Page must contain keywords
Set this option if you want to specify a list of keywords that an URL must contain before it is downloaded. You can enter one or more keywords line by line.
Page must not contain keywords
Set this option if you want to specify a list of keywords that an URL must not contain before it is downloaded. You can enter one or more keywords line by line.
Example:
You do not want to process files from folder "http://www.xyz.com/movies", so enter “/movies” in the exclude box so WDE will not download anything from that folder. Slash “/” is somewhat needed to make sure you filter a folder and not a file (movies.html).
Page must contain following text to extract data
Use text filter to extract data only from those web pages that contain text you specify. You can specify one or more keywords in the box and set “Match any”/”Match all” text.
Example:
If ”Match any” is set then WDE will accept a testing webpage that contains any of your keywords. If ”Match all” is set then a testing webpage must contain all of your keywords for WDE to start data extraction from that page.
Fixed number of pages
WDE will only go through set amount of pages
Authentication
First page authentication
If WDE comes across some website where registration is needed, it will ask you for your user login and password to enter the website
Extraction data
Custom data
Enables to enter Custom Data Editor
URLs, Domains, Meta Tags, Emails, Phones, Faxes
Types of information that can be extracted
Email filter
Email filter is used to filter emails during data extraction
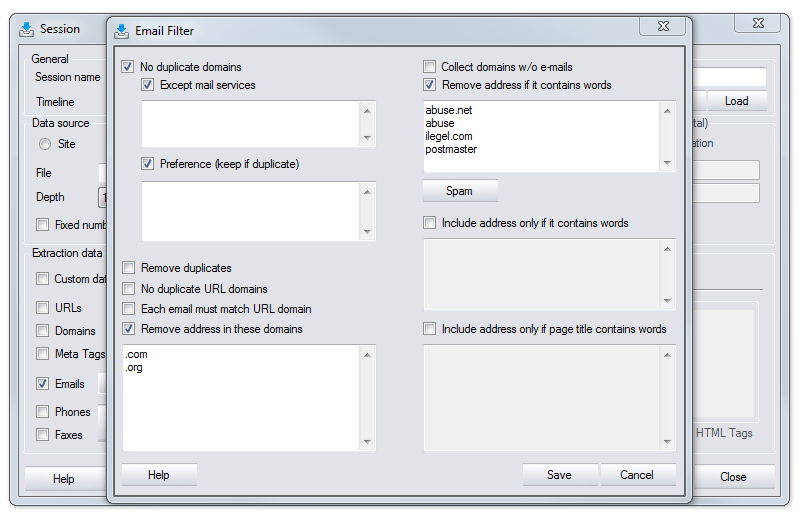
No duplicate domains
Check this option if you need only one email address from each domain represented in the filtered list. This is really useful when the list contains emails in corporate domains. Using this option you avoid mailing one message to the same company repeatedly. But at the same time you keep only one email address per a web-based service (domains Yahoo, Hotmail, MSN, etc.), where in fact each address belongs to a different person. To solve this problem there is a sub-option Except Mail Services.
Example:
The input list is:
- mary@company.com
- alex@magazine.com
- snail@yahoo.com
- smith@market.com
- jane@market.com
- twiggy@yahoo.com
- info@company.com
- job@magazine.com
- nicky@yahoo.com
f the option No Duplicate Domains is checked, the result will be as follows:
- alex@magazine.com
- mary@company.com
- smith@market.com
- snail@yahoo.com
Except mail services
Check this option together with No Duplicate Domains to keep in your list all email addresses which belong to domains that you list in the box below. In any other domain still only one email address will be kept.
Example:
The input list is the same:
- mary@company.com
- alex@magazine.com
- snail@yahoo.com
- smith@market.com
- jane@market.com
- twiggy@yahoo.com
- info@company.com
- job@magazine.com
- nicky@yahoo.com
If the options No Duplicate Domains and Except Mail Services are checked (and the Yahoo domain is indicated in the box below), the result will be as follows:
- alex@magazine.com
- mary@company.com
- nicky@yahoo.com
- smith@market.com
- snail@yahoo.com
- twiggy@yahoo.com
Preference (keep it duplicate)
This option allows you to specify more details in case duplicates occur within a domain.
For example, WDE came across two emails:info@company.com;
contact@company.com. If you activate this option and specify the word “contact” in the box below, then
the first email will be rejected (that is, placed to the tab Skipped) and the second one will be accepted (placed to the tab Filtered).
No duplicate URL domains
While the option Duplicate domains works with the domains that follow the '@' sign in email addresses, the option No duplicate URL domains is responsible for taking only one email address from each processed URL (web page).
Each email must match URL domain
WDE will look only for such emails whose domains match their own URL domains. Like abc@xyz.com and www.xyz.com.
Remove addresses in these domains
Check this option if you need to skip all email addresses from the specified domains. List these domains in the box below, one domain per line, starting with a dot (.org).
Collect domains without emails
Not all websites contain emails, even though they satisfy search criteria. That's when this option is useful – it lists these websites. Then on this base another program (ListMotor http://www.listmotor.biz/) will help you generate valid email list from the standard list of usernames (info, admin, support). This option is available only for Search Engines and URL List mode.
Example:
There is a website: abc.com, that doesn't contain any explicit emails. But it likely contains some service email (like admin@abc.com). With the help of WDE Pro and ListMotor you will get this email.
Remove address if it contains words
Use this option if you want to exclude email addresses containing specific words.
List these words in the box under the option, one word per line.
For example, if you put the word “bad” on the list, the following emails will be skipped:
badminton@sports.org, info@baden-baden.de, etc.
You can use Spam button to fill in the edit box of well-known spam sources.
Once edited, this setting remains valid for all further sessions until you change it.
Please note: you MUST NOT use WDE for spam purpose. We strongly discourage spam.
Include address only if it contains words
Check this option if you need to keep only email addresses that contain specific words. List these words in the box below, one word per line.
For example, if you put the word “nice” on the list, the following emails will be kept: city-of-nice@france.fr, info@venice.it, etc.
Include address only if page title contains words
Check this option if you need to keep only email addresses extracted from web pages where titles contain specific words. This words appear in the header of your Internet browser window if you visit the page. List these words in the box under the option, one word per line.
Custom data expressions
Custom data editor
This tool is developed to enable you extract items of information that have common visual structure from specified website. They are used to be called expressions or patterns. For example, to form a list of products of specified online store.
WDE finds information with the use of custom data expressions. To create such an expression correctly is a complex task demanding special knowledge. Custom Data Editor enables you to form and edit expressions automatically. This dialog can be accessed only in Data Source → Site mode. This dialog can be also accessed by hovering a cursor over the triangle button of Data1 (or other) tab.
Data1
Adjustment suit that sets the search mode of information container. You can view, add, remove or edit data piece(s) you created (25 data pieces maximum). To switch between data tabs you can use left-right, up-down keyboard buttons or ctrl+tab.
Begins with; Contains; Ends with
These boxes contain fragments of an expression that is built based on these fragments. When creating or editing expressions you can use “*” instead of any amount of any symbols and “|” to denote an alternative.
Example:
The complete expression:(?s)(?i)(?<=ttl">)(.*?< img itemprop="image" src=.*?)(?=
Contains:img itemprop="image" src=
Ends with: </a> </d
Help
Leads you to http://www.webextractor.com/help.htm
Start
Launch specified session
Close
Close session dialog
3. Custom data editor
This tool is developed to enable you extract items of information that have common visual structure from specified website. They are used to be called expressions or patterns. For example, to form a list of products of specified online store.
WDE finds information with the use of custom data expressions. To create such an expression correctly is a complex task demanding special knowledge. Custom Data Editor enables you to form and edit expressions automatically. This dialog can be accessed only in Data Source → Site mode.
This dialog can be also accessed by hovering a cursor over the triangle button of Data1 (or other) tab.
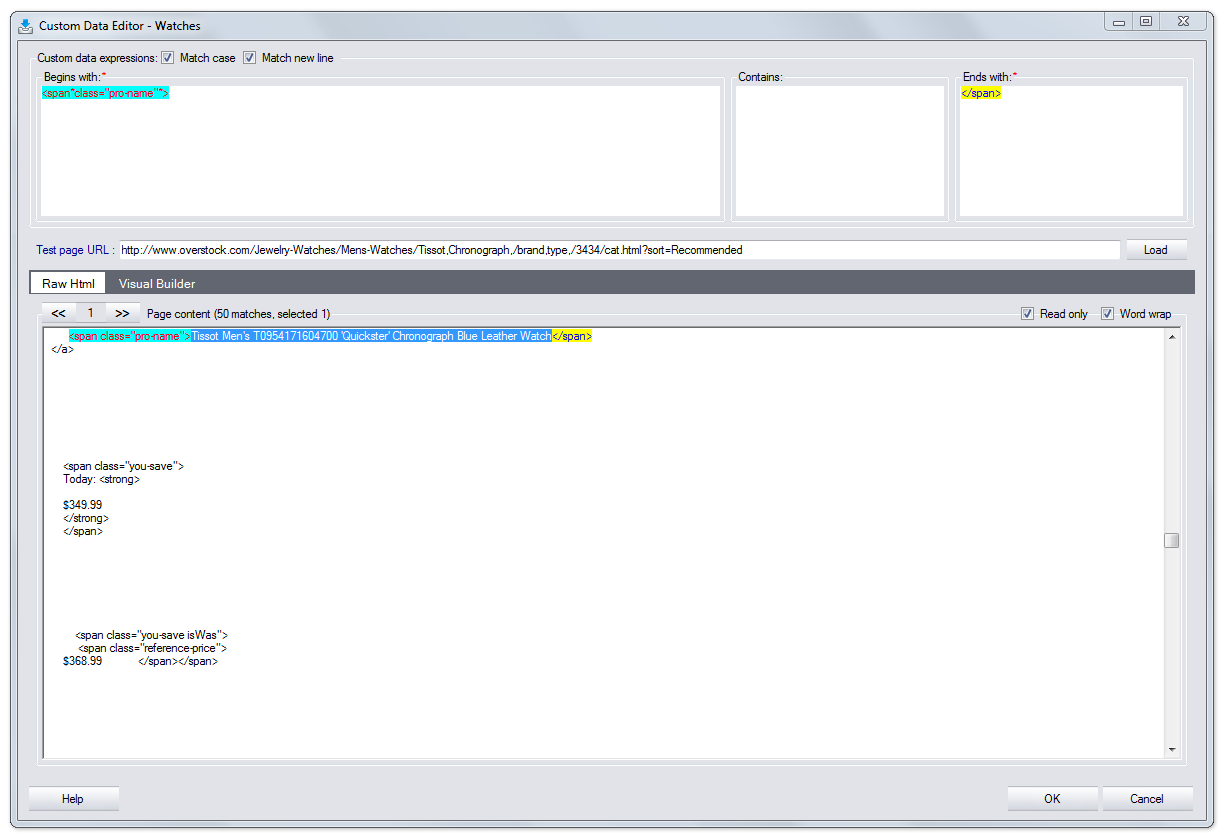
Match case
Case sensitive search of information containers (not default)
Match new line
Enables search of one expression in several lines (not default)
Begins with; Contains; Ends with
These boxes contain fragments of an expression that is built based on these fragments. When creating or editing expressions you can use “*” instead of any amount of any symbols and “|” to denote an alternative.
Example:
The complete expression: (?s)(?i)(?<=ttl">)(.*?
Begins with: ttl">
Contains:img itemprop="image" src=
Ends with:</a> </d
Test page URL
Enter an URL you want to work with and press Load
Page content box
Contains extracted HTML code of specified web page
Word wrap
No long strings scrolling
Visual expression builder
A dialog that helps you to view and navigate the web page to build expressions
Help
Leads you to http://www.webextractor.com/help.htm
OK
Apply expressions to specified session
Close
Close Custom Data Editor dialog
4. Visual expression builder
A dialog that helps you to view and navigate the web page to build expressions
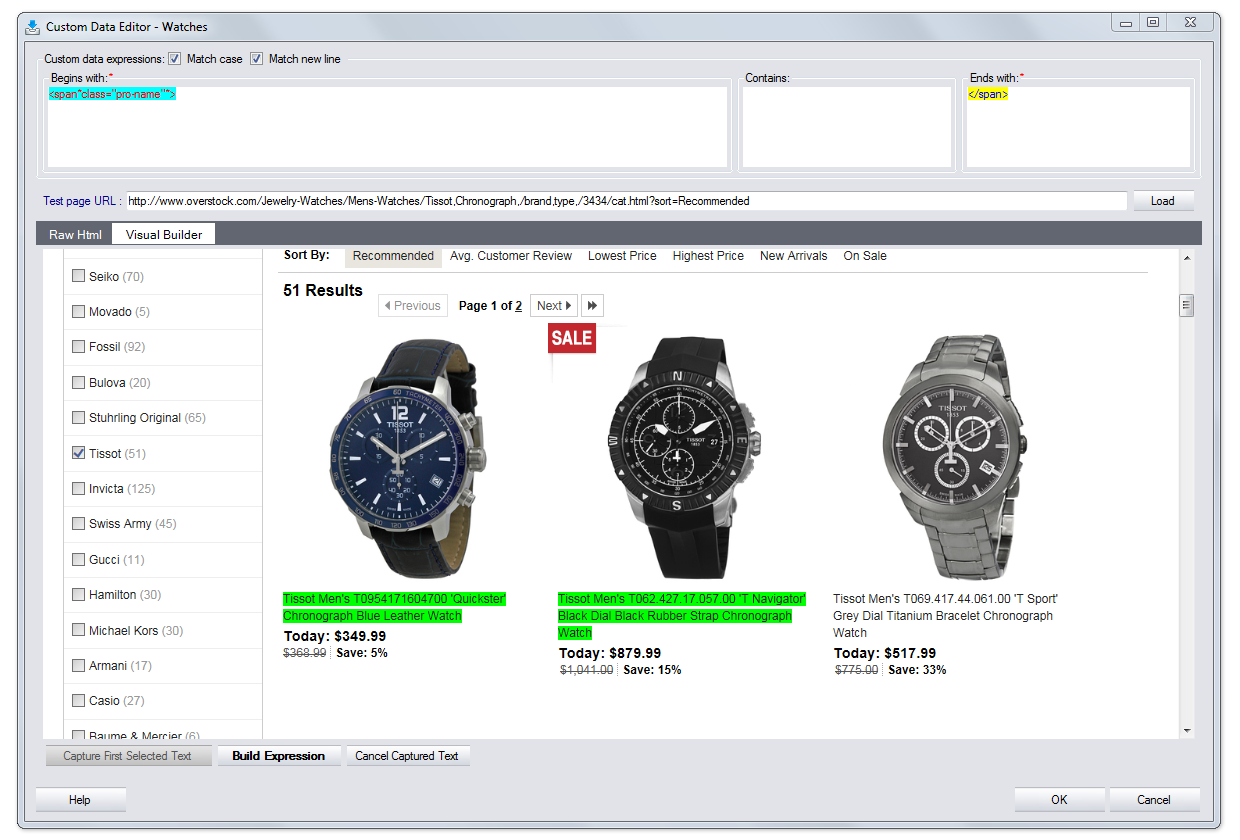
Navigation
Use the address line as in your common browser. You can follow a new URL (after you copied it to the clipboard) just by holding the Refresh button for a moment.
Selection
Activates expression building mode by locking page navigation and disabling selection of active content. In this mode all links are blocked by default. Uncheck to navigate website like in your common browser with Java and frames enabled. When processing similar containers, here will be displayed a number of items found.
The whole Selection section menu can be displayed by the right click on page content.
Lock current page
Enables a one-time link following returning to expression building mode right after that.
Information Container Backlight
This option helps to distinguish information container you have selected. To select/deselect the backlighted container use double click.
Precise selection
Is helpful when you need to distinguish a container (or a group of containers) from a more general container. When done, click 1st Item to Select.
Remove all unnecessary
Simplification of page display in case when there are problems selecting needed information
1st /2nd item to select
Determination of the minimal container for selected information unit.
Find all alike
An order for Visual Expression Builder to find all similar containers according to the search rule specified in an expression
Deselect
Deselect specified containers
Show more
Setting less strict rules of expression building. As a result, more similar containers with a common expression will be found.
Show less
Setting more strict rules of expression building. As a result, less similar containers with a common expression will be found.
Optimize an expression and apply
Reduce an expression to minimal value in such a way that units of information found will satay unchanged and apply it to Custom Data Editor. This helps WDE to work significantly faster.
Apply an expression without optimization
Apply an expression to Custom Data Editor without reducing it to minimal value
Flashing backlight of selected items
Helps to distinguish selected containers by flashing backlight
Show log
Opens Visual Expression Builder log file
Settings
Contains backlight, tool tips and history settings
Help
Leads you to http://www.webextractor.com/help.htm
In the bottom corners there is information on current process status.