
New Session
This section fully explains the options available for project setups. You can activate the New Session dialog by either launching a new session via the File-New menu item or the New Session button on the toolbar.
The Standard Project Setup Dialog box is shown below as covered in the 'How To' section along with additional explanations.
IMPORTANT: Before clicking "OK" button, always make sure that the window doesn't contain previous project's setting like URL Include/Exclude Filter, Date Modified Filter, etc. unless you want to run multiple sessions with same project setting. Also select what type of data you want to extract.
General Options
Keyword:
Enter the search keyword. It is visible when "Search Engines" source is selected. Click the "Engine" button to select/deselect specific engines. See: How to setup other search engines in the program?
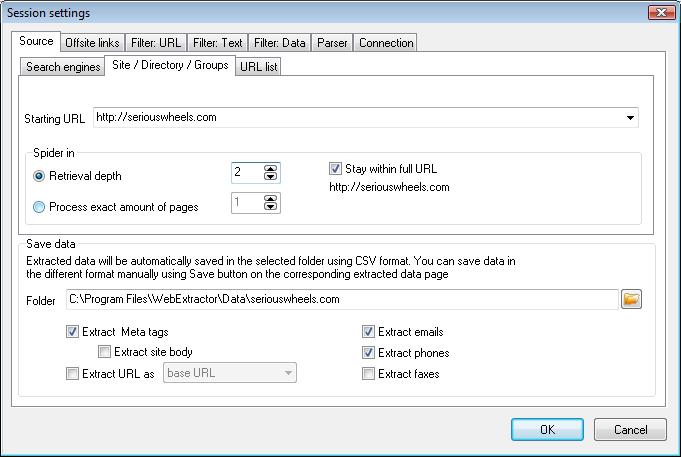
Starting Address:
Enter in the starting point URL such as a domain name or specific domain sub-directory. The drop-down arrow to the right of the text entry box will give you instant access to all previously used entries.
File Name:
Enter the filename that contains all URL links to process. It is visible when "URLs from File" source is selected.
Retrieval Depth:
Choose the retrieval depth - this tells program how many levels to dig down within the specified domain. Default setting is "0" and this will process whole site. A setting of "1" will only process the index or home page or current dir. More info about Depth
Stay within Full URL:
Choose this option if you want program to stay within the current URL. For example: specifying “www.xyz.com/product” will only scan files in the “product” directory and not those found anywhere else in “www.xyz.com” web site. De-selecting this option will build the entire site regardless of the URL entered.
Get First Page Only:
This option will process only the html page. For example: specifying “www.xyz.com/product” will only get that html page without any other files.
Save Data in Folder:
Select the destination folder where you want to save extracted data.
Save Data Line by Line: will store data line by line.
Save Data in CSV format: will store data with corresponding URL in comma separated value format, like:
"data", "url" . By default meta tags are stored in CSV format.
(You must set this option if you need to export extracted data to any database, or excel)
Extract:
Select what type data you want to extract.
External Site
Follow External Site:
Program finds lots of external sites, when processing starting site that specified in "General" tab. Check this option if you want to process/extract all external sites as well.
Retrieval Depth, Stay within Full URL, Get First Page Only behaves same as above "General" tab, except these settings are used only for external sites not for the main site specified in "General" tab. This facility allows the program to download only a mainpage (e.g yahoo, google dir page) , extract all external links found on the mainpage and process them one-by-one using separate setting specified in this section.
Spider Base URL Only:
This option tells program to always process the Base URLs of external sites. For example: if an external site found like "http://www.abc.com/product/free/utilities.htm" then program will process only base "http://www.abc.com/" ; NOT complete path "http://www.abc.com/product/free/utilities.htm"
Ignore Case of URLs:
This option tells program to ignore case of URLs. Some sites are case-sensitive, most of the sites are case-insensitive. When program is allowed to ignore case, then it will treat following 2 URLs as same:
http://www.abc.com
http://WWW.ABC.COM
File Filter - Date Modified
Use this option if you want to download and process only files that has been modified since certain date/time.
Note: Some web servers do not send file size/date information, so this size/date filter may not work in some cases.
URL Filter
Include:
Set this option if want to specify a list of keywords and tell program that a link/URL must contain any of those entered keywords before its files are downloaded. You can enter one or more keywords line by line. Every links or URLs will be checked before download.
Exclude:
Set this option if want to specify a list of keywords and tell program that a link/URL must NOT contain any of those entered keywords before its files are downloaded. You can enter one or more keywords line by line. Every links or URLs will be checked before download.
For example: you do not want to process files from folder "http://www.xyz.com/movies", so enter
/movies
in the exclude box and program will not download anything from that folder. The “/” is somewhat needed to make sure you filter a folder and not a file (zimovies.html).
Text Filter
Use text filter to extract data only from those web pages that contain text keyword you specify. You can specify one or more keyword in the box and set 'OR' / 'AND' logic. For example: if OR is set then WDE will evaluate true if the testing webpage contains any of your keywords. On the other hand, if 'AND' is set then all of your keywords must exist in that web page before WDE start data extraction from that page.
Email Filter
Use this option if you want to exclude specific type of emails, like abuse@, noreply@, complaint@, nospam@, .mil, .gov etc.
(Please note: you MUST NOT use WDE for spam purpose. We strongly discourage spam. No Spam )
Domain Filter
Check this option so that all extracted data is verified against domain list. By default it is checked always.
(To add new or additional domain - just open "DomainList.txt" file and edit it using NotePad or other text editor. You will find this file in program installation folder)
Proxy
If you access the Internet via a dial-up, xDSL, cable modem or LAN that DOES NOT use a firewall or proxy server, then select the Direct connection to the internet option. However, if you connection is through a firewall or proxy server, you will have to choose the Connect through proxy option and supply the required data.
Other Setting
Number of simultaneous server requests:
This controls the number of separate threads or connections that program will use to extract the project. The default setting is 10 which should work in most situations. If you have faster internet connection and efficient computer, you may use 15/20 threads. But remember, too high a setting may be too much for your computer and/or internet connection to handle and it also puts an unfair load on the host server which may actually slow the process down.
Request time out period:
This option will abort threads that show no activity for a certain period of time.
Agent:
The identity of WDE when communicating with remote servers.